Everyone is generating insights now. That's the problem.
Six months ago, the gap between teams that had data and teams that didn't was a real competitive advantage. Today it's gone. Any PM with a ChatGPT subscription can upload a research transcript and get back a themed summary in four minutes. Any founder can paste in NPS comments and receive a priorities matrix. Any exec can ask for a strategic synthesis of last quarter's user feedback and have it on their screen before their coffee cools.
AI democratised insight generation. Which sounds like progress; except it created a new problem nobody prepared for.
When everyone generates insights independently, you don't get more clarity. You get more conflict. The PM's AI tells him users want frictionless onboarding. The designer's AI tells her users don't trust the product enough to hand over their data. The CPO's AI tells him the funnel is the bottleneck. Three people, three tools, three contradictory conclusions; all of them confident, all of them well-formatted, none of them quite right.
The insight was never the bottleneck. The system to arbitrate between insights was.
This is what Insight Ops is about. Not another framework for running research. A governance model for deciding which insights are real, which ones should change a decision, and how that signal gets from the data to the person holding the roadmap; before the decision locks.
But first, we need to agree on what insight actually is. Because most of what teams are generating right now isn't insight. It's synthesis. And those are not the same thing.
Synthesis is what AI does well. Feed it a hundred transcripts and it will find the themes, cluster the language, tell you that 67% of users mentioned confusion in the onboarding flow and that three distinct pain points surfaced across segments. It will do this faster than any research team you can hire, and present the findings with a confidence that looks authoritative. But synthesis compresses signal. The things that appear most often rise to the top. The things that appear once (the outlier, the anomaly, the response that directly contradicts the pattern) get compressed into a footnote or disappear entirely.
Real insight is counterintuitive. It reframes the problem. It contradicts what you walked in expecting to find. It's not a tidy summary of what your users said; it's the moment where the data corrects your assumptions and you feel it. Not organised data. A correction.
AI will give you organised data. It will not give you the adrenaline moment where reality corrects your assumptions. That moment requires a different kind of system; one designed to find what wasn't expected, not to surface what was. And that system is what most teams don't have.
The leader has to buy in first. But the practitioner builds the case. Top-down adoption, bottom-up evangelism.

Three ways the system breaks
The five-step method for finding real insights (counterfactual hypotheses upfront, line-by-line interrogation, hunting anomalies, correlation passes, distilling to one) is necessary but not sufficient. Because even when the method works, the insight still has to travel from the data to the person making the decision. And that last mile is where most teams lose it.
Three ways it breaks. All of them real. All of them from the same career.

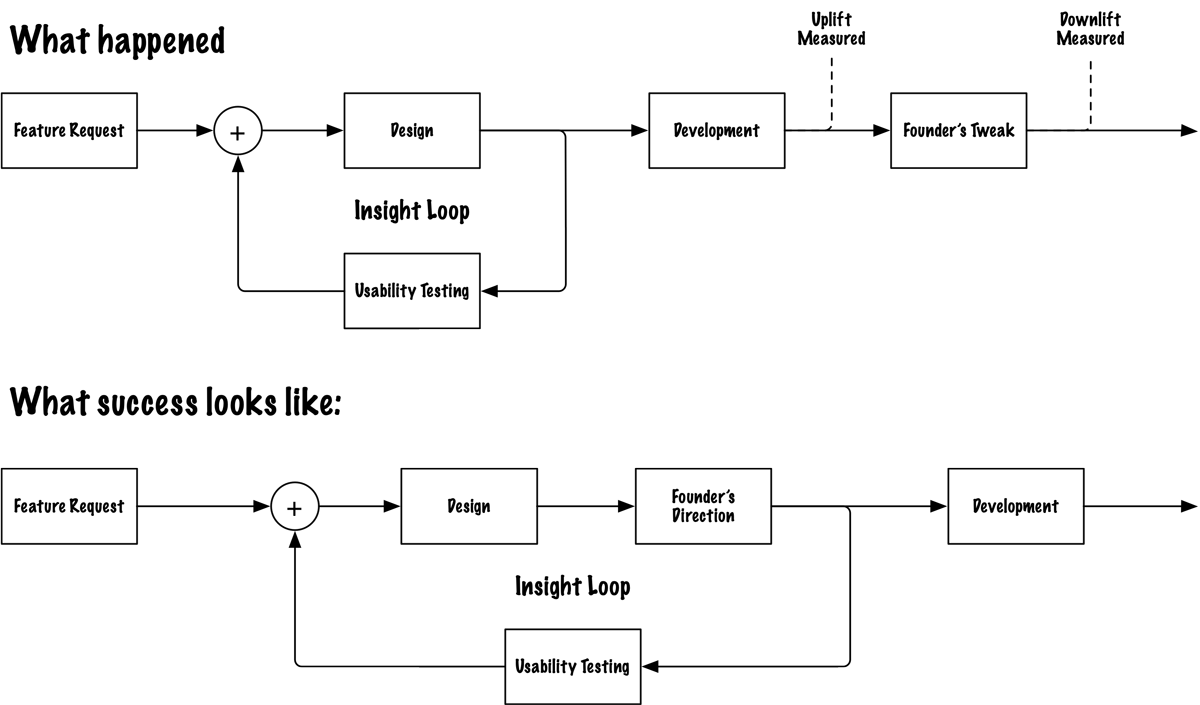
Failure Mode 1: Research doesn't reach the decision in time
At CarExpert, we had done the work. Collaborative design sessions, usability testing, a thorough process that produced a clean, considered buy page. The kind of page that breathes; white space, clear hierarchy, a single value proposition at the top.
Then a founder rewrote it overnight.
He had a journalist's instincts and an SEO background, and he was convinced he knew the audience better than the research did. The page he shipped looked like a mailbox brochure; text-heavy, urgency signals competing for attention, every element screaming at once. We flagged it. We provided the rationale. He couldn't be moved.
The numbers tanked after launch. We suggested reverting. By then the damage was visible; but it had already shipped.
The failure here wasn't the research. The research was right. The failure was structural: there was no checkpoint in the process that required research to sign off before a significant change went live. The decision window opened and closed without the insight ever entering the room.
What Insight Ops requires here: a pre-shipping gate. Not bureaucracy; a single rule: any change to a validated design requires the rationale to be surfaced and assessed before deployment. The insight doesn't need to win. It needs to be heard before the decision locks.
The operating model shows what that gate looks like in practice.
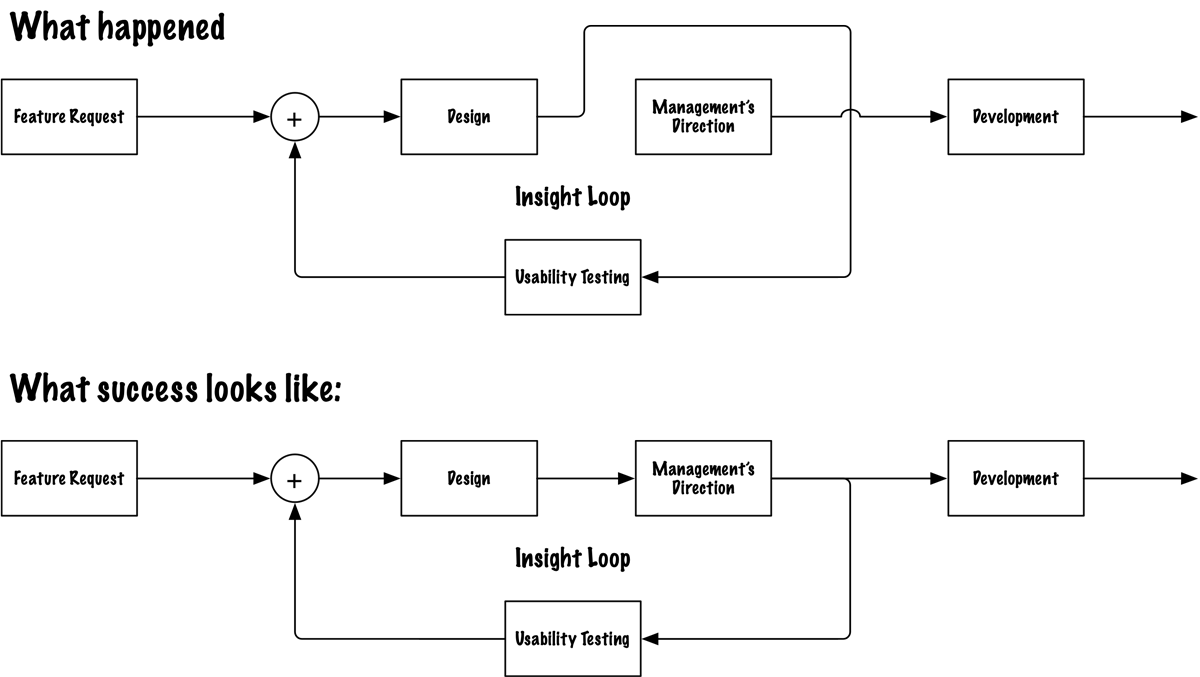
Failure Mode 2: The insight exists but the frame is wrong
At Compare Club, we ran a study on bill upload methods. The data was thorough. The pattern was clear: users prioritised reliability and predictability over convenience. They had high tolerance for extra steps if those steps felt safe. A process that seemed "too fast" felt suspicious.
And yes; they liked the idea of email connection. It felt effortless. Smart. They would absolutely use it.
Once they trusted the product enough to hand over inbox access.
That last sentence was the insight. Trust was a prerequisite, not a byproduct. The feature depended on a trust handshake that didn't exist yet.
We delivered the finding. The business heard "users like email connection" and shipped it anyway. The prerequisite got buried between the readout and the roadmap.
We framed the insight as a preference when we should have framed it as a blocker. Those are not the same thing and they don't produce the same decision.
What we said: Users prefer email connection; it feels convenient and effortless.
What we should have said: This feature depends on a trust handshake that doesn't exist yet. Shipping without it means low adoption and no way to diagnose why; because the data will read as "users don't want this" when the actual problem is "users don't trust us enough yet." Different problems. Different solutions.
What Insight Ops requires here: a reframe discipline. Before any insight is presented, one question: am I framing this as a preference or as a constraint? Constraints block decisions. Preferences inform them. Know which one you have before you walk into the room.
The operating model turns this into a repeatable check.
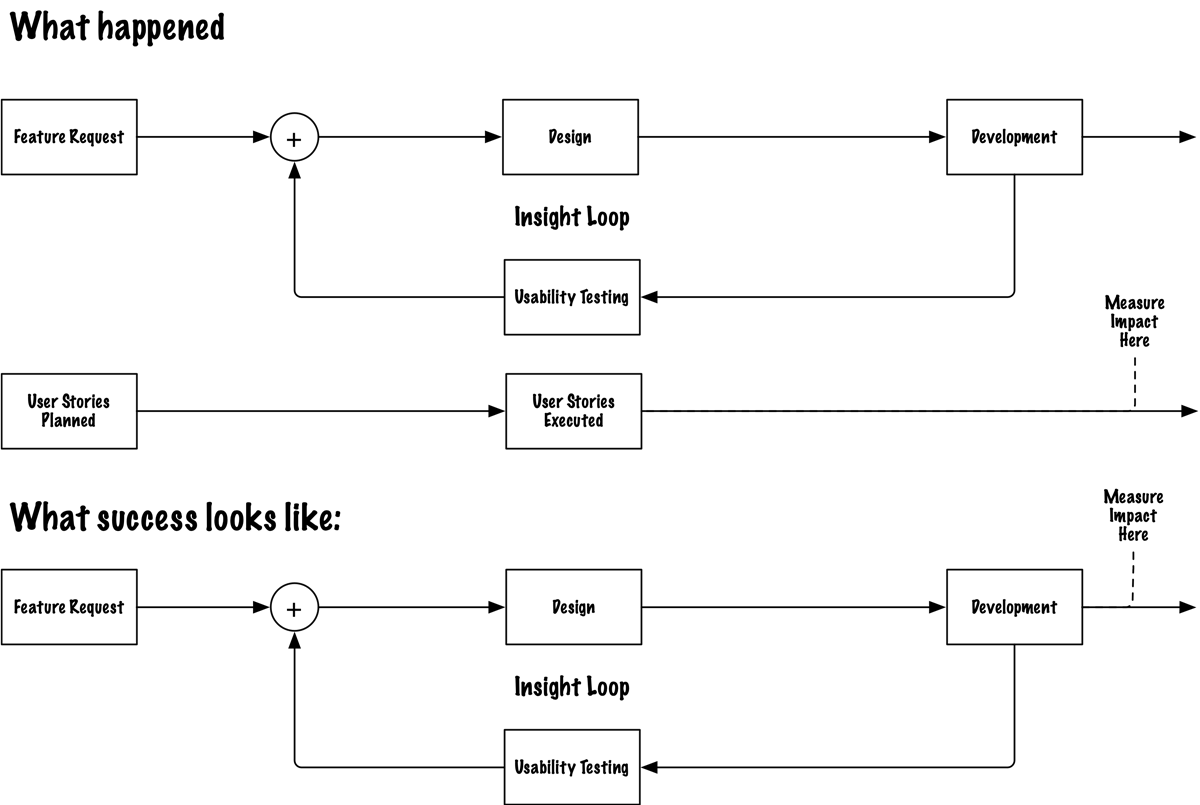
Failure Mode 3: The incentive isn't aligned with the insight
At Compare Club, a PM proposed an A/B test with a flaw my CRO lead and I both spotted immediately. The form made a silent promise ("this is all we need") and broke it one screen later. Not reduced friction. A bait and switch. Users who feel deceived don't just drop off. They don't come back.
We proposed three variants that would actually surface something useful. The PM acknowledged the flaw. Nodded. And shipped the original test anyway.
His reason: the pipeline was full. An ABC test would take longer to reach statistical significance. He didn't have bandwidth.
But here's what was really happening: his success was measured by tests delivered, not by conversion lift from validated changes. So when I came with research that said "slow down and do this right," I was attacking his metric, not informing it. The insight was irrelevant to how he was being evaluated.
My CRO lead and I ran separate analyses afterward (independently, using ChatGPT) hoping to build a case strong enough to reopen the conversation. His instance and mine reached contradictory conclusions from the same data. Which, if anything, made the PM's decision to move on feel more defensible. The noise from competing AI analyses had become its own kind of cover.
The decision window had already closed. The insight came too late and into the wrong incentive structure.
What Insight Ops requires here: metric alignment before research starts. One question: what is the decision-maker actually being measured against? If the answer isn't connected to the outcome your research is measuring, the insight will never land; not because it's wrong, but because it's speaking a language nobody at the table is being paid to hear.
The operating model makes this the first question, not the last realisation.
When research is weaponised
There is a failure mode the system can't fix. It's when the research was never meant to produce an insight. Early in my career at , a client commissioned a research project with a legitimate-sounding brief; consolidate thirty-odd website properties into a smaller portfolio, data to inform the decision. We did the work. Thorough analysis, clean findings, solid recommendations. She looked at the output and told us it wasn't going to cut it. She already knew the answer. She needed 's name on a document that said what she had already decided to say. This happens more than anyone in the industry admits; leadership commissions research after a strategic decision has already been made, not to test it but to legitimise it. The only honest response to a brief like that is to name it upfront: before we start, if the research contradicts the direction, that needs to be on the table.
What Insight Ops requires here: a pre-engagement gate. Before the first data point is collected, add the gaming guard: we'll test your direction, but here's what success looks like and what we do if it doesn't. That conversation separates the clients who want insight from the clients who want cover.
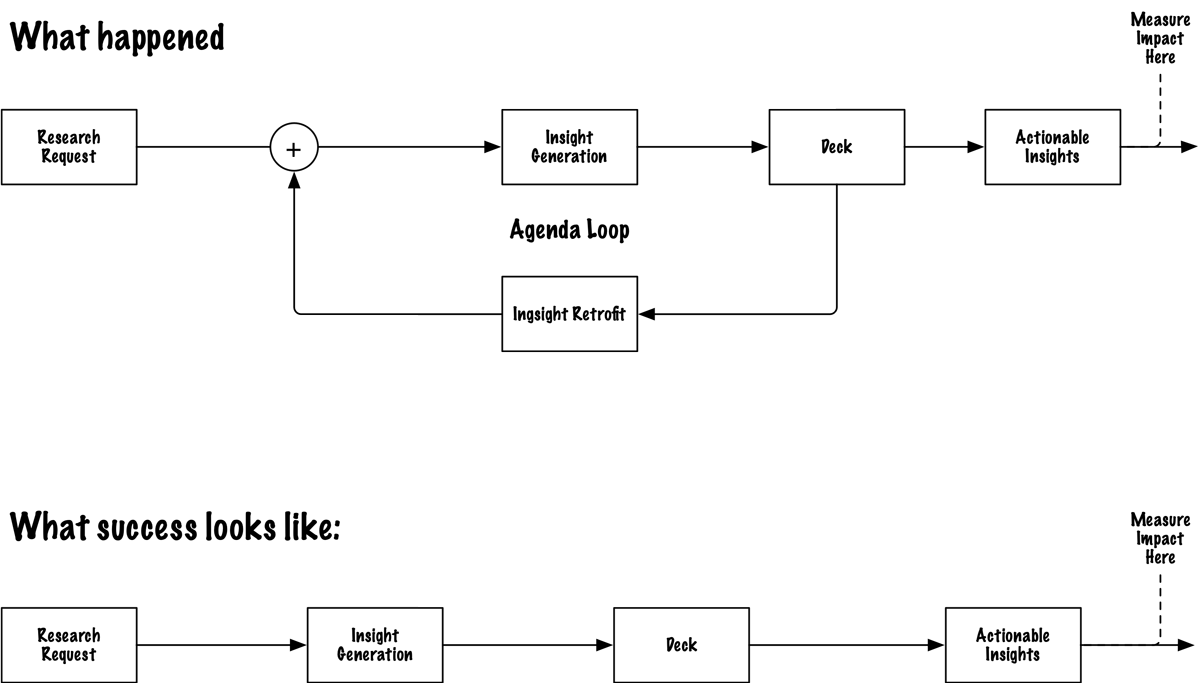
The operating model
Most teams treat research as a deliverable. You run the study, write the report, present the findings, move on. The insight exists as a document. Whether it changes anything is someone else's problem.
Insight Ops treats research as a control system. And the first thing a control system needs isn't a better sensor; it's a governance layer that decides what to do with the signal.
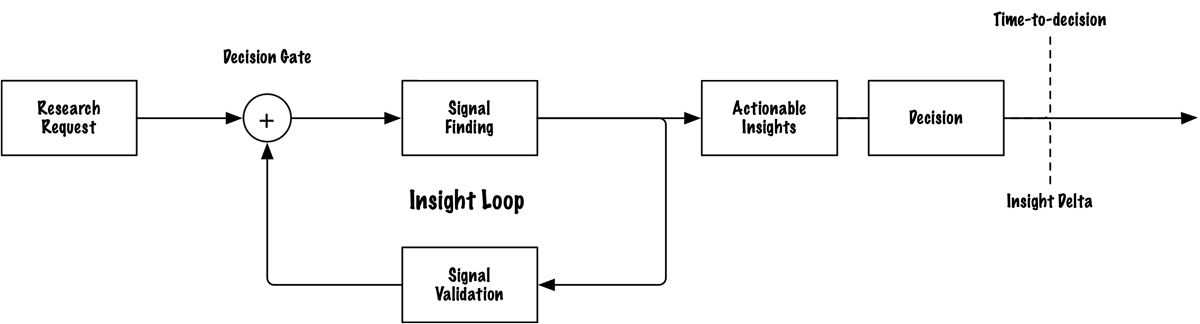
The two metrics
Insight Ops runs on two numbers.
Insight Delta: which decision actually changed because of this research? Not "what did we learn"; what did we do differently than we would have done without it? If the decision would have been the same without the research, the research didn't produce an insight. It produced a document.
Time-to-Decision: how long from the first research touchpoint to the moment the decision was reached? A slow loop means decisions lock before insights arrive. A fast loop means research is part of the decision process, not a report that follows it.
At Compare Club, Jesse was confident in one colour direction for the confidence gauge. The research showed a four-way deadlock neither of us expected. We redesigned the control entirely. That's Insight Delta; the decision changed. Time-to-Decision was three to four days using Askable.
Track both. If Insight Delta is low, the method is broken; you're finding things but framing them wrong or surfacing them too late. If Time-to-Decision is high, the system is broken; the loop is too slow to influence anything.
Time-to-Decision is your early warning. Insight Delta is your audit trail. One tells you the loop is too slow. The other tells you the loop isn't working.
The decision log
The operating model only compounds if you record it.
For every project: what was the question, what did the research find, what decision did it affect, what actually happened. A status field; acted on, ignored, superseded, pending. That status field is the honest accounting. Over time it tells you exactly where your organisation's loop is breaking.
At Compare Club, the act of tracking exposed a pattern nobody had named: "we tried that before and it didn't work" was being used as a conversation-stopper with no evidence behind it. The log forced intellectual honesty. Once you can point at a row and ask "when did we try it, what did we measure, and what happened?" the conversation-stopper loses its power.
Six months of this log is worth more than most portfolios; it's the raw material for the correlation passes in your next project.
Research question | Key finding | Decision affected | Status | Outcome at 90 days |
|---|---|---|---|---|
Which colour direction builds confidence in the gauge? | Four-way deadlock; no single colour won. Control itself needed redesign. | Gauge visual design | Acted on | Redesigned control shipped; confidence scores improved. |
Do users trust email connection for bill upload? | Users liked the concept but lacked the trust prerequisite to grant inbox access. | Email connection feature rollout | Ignored | Low adoption; trust gap misread as lack of demand. |
Does the proposed buy page improve conversion? | Research-backed design outperformed; founder's overnight rewrite broke hierarchy and clarity. | Buy page layout | Superseded | Metrics tanked post-launch; revert came too late. |
The critique cadence
Once a month, one meeting with one agenda: what has changed since we set this direction?
Not a retrospective. Not a sprint review. A strategic sense-check where the question on the table is whether the direction is still right; not whether execution was fast enough.
Public commitment creates psychological lock-in (the CPO who couldn't reverse a mobile-first strategy despite the data is a textbook case). The critique cadence is the mechanism that overrides it; structured permission to revisit strategy without it reading as failure.
This is what breaks first. The monthly sense-check gets cancelled when things are busy; which is exactly when it matters most. The loop closes at the execution layer but never reaches the strategy layer. Leadership has to treat this ritual as load-bearing infrastructure, not a nice-to-have that yields to sprint pressure.
The five-step method
The method for finding insights; counterfactual hypotheses, line-by-line interrogation, anomaly hunting, correlation passes, single-insight distillation; was covered in Part 1. The operating model above governs what happens after those insights exist. The method finds them. The governance layer makes sure they land.
The feedback loop
The whole system works as a bidirectional context loop; a term from recent HCI research on human-agent collaboration. Every action in the system updates the shared context that drives the next decision. Research informs the decision. The decision's outcome feeds back into the next round of research. The loop is continuous. The system self-corrects. At Compare Club, the gauge redesign changed how we scoped the next study; we stopped asking "which option do users prefer?" and started asking "what is the control itself failing to communicate?" The finding from one row in the decision log rewrote the research question for the next.
2025 CHI paper (arXiv) on how shared context between humans and agents drives emergent, iterative decision-making.
This is not a description of how organisations work today. It is a target architecture; what the system needs to look like for Insight Ops to function. Most organisations run open-loop. Decisions get made. Metrics get reported. But the measurement rarely feeds back into the strategy layer in time to change anything. Insight Ops closes the loop. Not once a quarter. Continuously.
Three preconditions
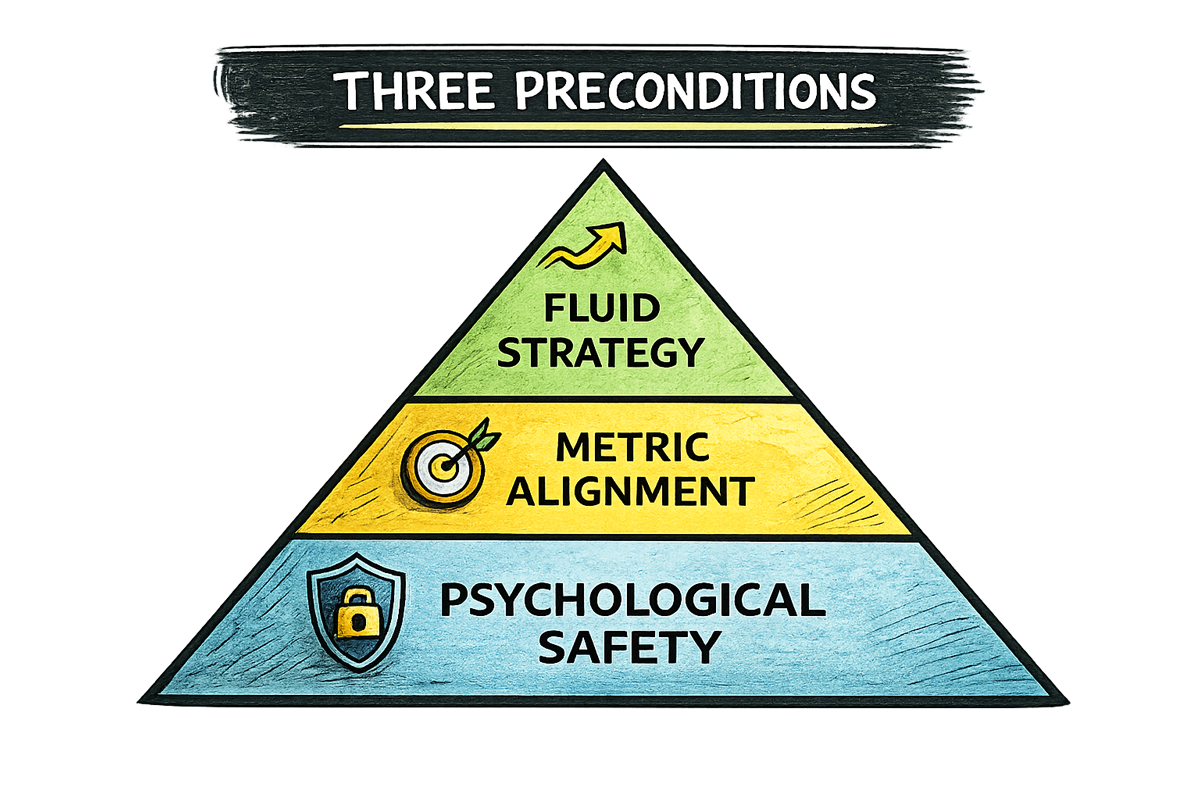
The operating model is useless without what sits beneath it. Every one of the failure modes had a method problem on the surface. Underneath each was the same structural problem: the system lacked the conditions for the insight to move.
1. Psychological safety as infrastructure. The PM who needs to stop a flawed test sits one level below a manager. That manager sits below a CPO. The CPO sits below a CEO. For the PM to pause, he needs to believe his manager will back him. For the manager to back him, the CPO can't punish the delay. For the CPO to absorb it, the CEO can't read it as a lack of execution discipline. It's fractal; the same trust structure repeats at every level. Break it at any point and the insight stops propagating upward. It stays local, gets noted, gets filed. The loop never closes.
2. Metric alignment. The PM shipping the flawed A/B test wasn't malicious. He was rational. He was being measured against delivery speed, so he delivered. Measure people against proxies, they optimise for proxies. When an insight arrives that would slow the proxy down, it gets overridden; not because people are ignoring the data, but because they're rationally responding to what they're being evaluated against. Fix this before research starts: what is the decision-maker actually being measured against? If that metric isn't connected to the outcome the research is measuring, either change the metric or change who you're presenting to.
3. Fluid strategy. Strategy documents are optimised for commitment, not responsiveness. The more publicly they've been articulated, the harder they are to revise without it looking like failure. A 2026 CHI study on human-agent collaboration found that user intent is not a static upfront specification; it's emergent, incrementally refined through interaction. If that's true of individual users navigating a single task, it's doubly true of organisations navigating markets. When research shows the direction is wrong, changing the direction is not failure. It is the system working.
Insight governance is the new competitive advantage
AI made insight generation cheap. It's table stakes. Any team with a subscription and an afternoon can produce a themed synthesis, a prioritised findings deck, a strategic summary of user feedback. The tools are good. The outputs look authoritative. Almost none of it changes decisions.
The organisations that pull ahead won't be the ones generating the most insights. They'll be the ones with a system for deciding which insights are real, which ones should change a decision, and how that signal reaches the person holding the roadmap before the window closes. That system is Insight Ops. Right now, almost nobody has it.
Start here
Three tiers. One concrete move each.
If you lead a team: Run the audit this week. Pull the last five significant decisions. For each one: was research in the room before the decision locked? If not; was the insight surfaced too late, framed wrong, or ignored because nobody had the safety to raise it? That audit tells you where the loop breaks.
If you are a practitioner: Write two sentences before your next project starts. First: what would prove us wrong? Second: what is the decision-maker being measured against? If you discover the metric doesn't align, don't walk into the room alone.
Socialise the finding with friendlies first. Send a Slack DM to someone who's seen the same pattern. Pull them aside after standup for a two-minute hallway debrief. Find someone with credibility in the org and let them carry it forward. Be willing to give away the win; credibility is earned, not assumed, and an insight that lands through someone else's voice still landed.
If you are building AI into research: Stop using it for summaries. Start using it for interrogation. Ask it what's missing. Ask it what contradicts the pattern. Ask it which response doesn't belong. The summary is the easy part. The anomaly is where the insight lives.
The question that started this
A few months ago my manager asked me why I wasn't doing the screens.
The visible thing; the synthesis, the summary, the deck, the feature, the test; isn't the point. It never was. The point was always the decision it was supposed to inform.
Execution was expensive enough for long enough that we all forgot that. AI just made the forgetting impossible to sustain.
The insight was always the point. Insight Ops is the system that makes sure it lands.