Nobody was using them anyway
At some point in the last decade, every UX team in the country produced a set of personas. Laminated, maybe. Named after someone's attempt at a clever pun. Printed on A3 and stuck to a wall that nobody walked past.
Six months later, they were in a folder in Google Drive. A year later, nobody remembered the folder name.
The drawer is not the failure mode. Keeping a persona alive past its useful life is. Personas are tools, not assets; retire them when the problem evolves.
Personas arrived alongside UX itself; a generation from marketing, psychology, and journalism decided to become designers, and the process was new. Personas looked rigorous. They had sections, photos, a quote in italics meant to sound like a real person. Teams built them not because they were solving a specific problem, but because personas were part of the process.
The research was often real. Companies spent forty, sixty thousand dollars on thirty interviews, weeks of synthesis, a research firm with a beautiful deck. And then the personas went into the drawer. Not because the research was bad; because the personas were never tied to a decision. A persona that tells you your user "values work-life balance and enjoys cooking on weekends" is not a design tool. It is a LinkedIn profile for a fictional person.
That is where personas were when AI arrived.
The cost was the conscience
There was one thing the old model got right, even when everything else went wrong. It was expensive.
When you spend sixty thousand dollars on a research piece, someone in the room will eventually ask: how do we know this is true? Not because they care about epistemology; because they care about sixty thousand dollars.
That question is the most important question in research. It forces you to articulate your sample, your methodology, your confidence level. It forces you to admit what the data cannot tell you.
I ran a study at CarsGuide. Thirty-two interviews across two weeks, another month to synthesise. The personas ended up in a drawer (same as everyone else's), but one insight moved the needle; the awareness gap that nobody in the Australian car-buying space had claimed. Every competitor was fighting over consideration and decision. Awareness was sitting there, uncontested.
That insight came from the interviews, not the personas. The personas were the container that justified the spend, which justified the time, which created the conditions for the insight to surface.
And then AI arrived and the cost collapsed. Twelve personas in twenty minutes. No recruiter, no firm, no invoice. No one asking how do you know this is true?; because there is no room, no invoice, and the question that used to be forced by circumstance now has to be summoned by discipline.

AI made the question skippable
Not harder. Skippable.
The complaint about AI-generated personas is usually framed as a quality problem; the outputs are shallow, the people are fake, the insights are hallucinated. True, but beside the point. Shallow personas existed long before AI. The drawer is full of them. The real problem is structural.
When research was expensive, how do we know this is true? had a natural home; the budget meeting, the client presentation, the moment someone looked at a sixty-thousand-dollar invoice and decided it needed to be defensible. When research is free, the question has no home. It has to be invited. And in a product team under pressure to ship, an uninvited question does not get asked.
This is what makes AI-generated personas genuinely dangerous in a way bad research never was. Bad research announced itself through its cost; you knew someone would scrutinise the output. AI-generated personas arrive with no such signal. They have the structure of research (names, motivations, frustrations, behavioural patterns), the language is confident, and nothing about the output tells you whether it is grounded in anything real or assembled from statistical plausibility.
The junior designer who generates twelve personas in an afternoon is not doing something wrong on purpose. They are doing something that looks exactly like the right thing. Nobody handed them a filter. The hard part (whether these personas are grounded in actual behavioural signal) is invisible in the artifact.

Focus on the behaviour you want to change
Here is the thing about the drawer problem. The personas that ended up there were not useless because they were poorly made. They were useless because they were made to describe people instead of decode behavior.
What follows is built on three ideas: behaviour-first framing, the two-by-two (drawn from Fogg's model), and a grounding loop that keeps the whole thing honest.
A persona that tells you someone is a "busy professional who values efficiency" has described half the population of LinkedIn. It cannot tell you what to build. It cannot tell you where the funnel breaks. It cannot walk into a product meeting and change a decision.
A persona built around a specific behavioral question can do all of those things.
The shift is smaller than it sounds. You are not abandoning the persona format. You are changing the question you start with. Not who is this person? But what behavior are we trying to change, and what is stopping it?
BJ Fogg spent years at Stanford working on this. His model is deceptively simple: behavior happens when motivation, ability, and prompt converge at the same moment. Remove any one of them and the behavior does not occur. It does not matter how much someone wants to do something if they lack the ability. It does not matter how capable they are if nothing prompts them to act. Fogg gives you vocabulary for empathy; ability and prompt are the mechanism to practise it at a structural level.
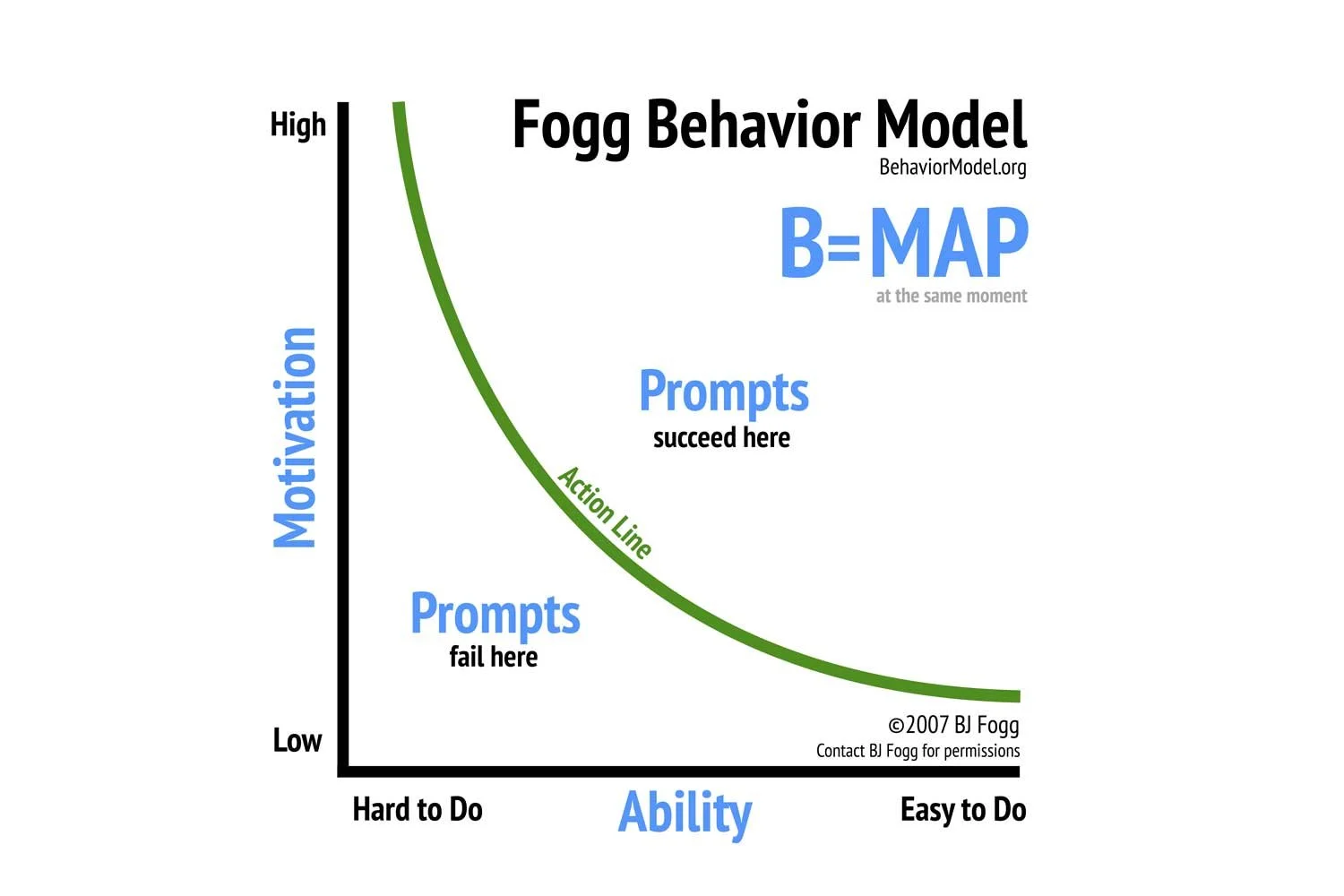
I did not start building personas with Fogg in mind. I started building them because the old way was not working — too many attributes, too little traction, too many personas nobody could remember. I ended up at a two by two. Two levers on two axes. Four behavioral types at the intersections.
It was only later, looking back, that I recognised what the axes actually were.
For Club+ — a platform that helped members store and manage their insurance documents — the two levers were simple. Ability to stay organised on one axis. Willingness to receive and act on advice on the other. High and low on each gave four distinct behavioral types. Not four demographics. Four different relationships with the problem the product was trying to solve.
That is the move. Not who are your users but what are the levers that govern whether they do the thing you are designing for?
The two by two constrains the complexity before it starts. More than four personas and you are adding cognitive load to every product decision that follows. Fewer than four and you are probably flattening real variation. Four is the number that fits in a meeting room and survives a sprint.
The four types that emerge from the intersections are not character sketches. They are behavioral profiles. Each one tells you something specific: what this person needs in order to act, what is stopping them, what a well-designed prompt looks like for someone at this point on both axes.
And here is what Fogg's model adds that most personas miss. Motivation is not the primary lever. Fogg is explicit about this — motivation is volatile, expensive to move, and unreliable as a design target. Ability and prompt are where the design work actually lives. You meet the user where their ability is. You design the prompt for the moment when motivation is already present.
The personas that changed Club+ were not better researched than the segments that preceded them. They were better aimed. They were pointed at behavior, not biography. And because they were pointed at something specific, they could walk into a room and change a decision.
That is the only test that matters.
The grounding looks different every time
Here is where the methodology earns its keep; and where most write-ups about synthetic personas quietly fall apart.
The two by two is not a shortcut. It is a frame. And a frame is only as good as what you put inside it. The behavioral levers you choose — the two axes that generate your four types — are not self-evident. They have to come from somewhere real.
The somewhere real looks different every time.
For Compare Club's life insurance vertical, I had five hundred call centre transcripts. Real conversations between real customers and real agents. I ran them through a data pipeline, extracted the signal, and asked: what are the recurring moments where behaviour breaks down? What is the ability gap? What is the prompt that is missing or misfiring? The levers that emerged were Readiness to Buy on one axis, Price Sensitivity on the other. I did not invent them; the data surfaced them.
For other projects, the entry point was different. Sometimes it was five interviews with people already using the product; not a formal study, just enough conversation to hear the pattern before it stopped being surprising. Sometimes it was expert knowledge inside the company — the support lead who had spoken to more users in a year than the research team had in three, the sales rep who knew exactly which objection killed every demo. Sometimes it was a scrappy spread of conversations across as many different user types as possible, not to achieve statistical significance but to make sure the variation was audible before the synthesis began.
Your access to signal determines your approach; that is fine. The methodology adapts to what you can reach. The rigour is in refusing to skip the grounding step, not in the volume of data.
You are always listening for the same two things. Where does ability break down — where do users hit a wall they cannot get past, regardless of how much they want to? And what is the prompt dynamic — what triggers action, what is missing, what arrives at the wrong moment or in the wrong form?
Everything else is context.

This is the answer to the question that hangs over every synthetic persona: how do you know it is true? You know it is true the same way you know anything in research is true; because it is anchored in signal, not assembled from plausibility. The signal can come from transcripts or interviews or corridor conversations with the customer success team. What disqualifies it is having no anchor at all.
For someone early in their career, without a data pipeline or a research budget or five hundred call transcripts sitting in a folder; the answer is still the same. Talk to five people. Not thirty-two. Not twelve. Five, if that is what you have. Ask the customer-facing people in the company what they hear every day. Look at support tickets. Read the one-star reviews. The signal is almost always available. The question is whether you are looking for it before you open the design tool.
The grounding is not the data pipeline or the interview guide or the call centre transcript file. The grounding is the willingness to be wrong before the persona goes into a meeting and starts making decisions. (What happens when you actually test that willingness against people who disagree with you is a different skill entirely; that comes later.)
Friction emerges through interaction, not interviews
This is the part that traditional research cannot do.
Ask someone in an interview where they get frustrated with a product and they will tell you what they remember, filtered through what they think you want to hear, shaped by the distance between the frustration and the moment they are describing it. That is not nothing. But it is not the same as watching what actually happens when a specific type of person hits a specific step in a specific flow.
Synthetic personas can do the second thing. If you build them right.
Once the personas are grounded — once the levers are anchored in real signal and the four types are defined — you can walk them through the product. Not metaphorically. Step by step, screen by screen, decision point by decision point. The Markov unit is the screen. You ask: what does this persona do here? What is their ability at this moment in the flow? Is the prompt landing? What is the likelihood they continue?
If you assign values to the behavioral dimensions — ability rated zero to one, prompt responsiveness rated zero to one — you can derive a behavior score for each persona at each step. String those scores across the full funnel and you have a Markov chain (a model of the probability that each persona completes each step in the journey). The Markov model deserves its own post; this one is about the question that precedes it.
This is what I mean when I say friction emerges through interaction. You do not ask the persona where it hurts. You run the persona through the flow and watch where the scores drop. Where does the probability of continuation fall below the threshold that makes the next screen worth building? That is your friction. Not reported. Revealed.
At Club+, this is what changed the conversation. The personas did not just sit on a wall and describe people. They traversed the product. They surfaced specific moments where a particular behavioral type would stall — where the ability gap was too wide, where the prompt was arriving too late, where the design was optimised for one type at the direct expense of another.
Those moments became the product roadmap.

The other thing this reveals — and this is the finding that surprises people every time — is that the same screen can work perfectly for one behavioral type and fail completely for another. Not because the design is bad. Because the two personas arrive at that screen with different ability levels, different prompt sensitivities, different prior steps in the journey that have either built or eroded their confidence.
A one-size-fits-all flow optimises for the average. The average user does not exist.
When you run four personas through the funnel, you stop designing for the average. You start designing for the range. You make explicit decisions about which behavioral types the product is built to serve, which ones need a different path, and which ones are outside the scope of what this version of the product can do.
That is a harder conversation than "users prefer option A." It is also the conversation that actually changes what gets built.
The irony is that this approach produces the thing traditional research always promised and rarely delivered: a direct line from user understanding to product decision. Not via a deck. Not via a presentation that gets noted and filed. Via a model that sits inside the design process and answers a specific question at every step of the funnel.
That is what my manager got excited about. Not the personas themselves. What they could do.
You can be wrong about the levers
This is the section most methodology write-ups skip. Because it is uncomfortable.
Everything described so far — the two by two, the behavioural levers, the Fogg model, the Markov chain through the funnel — is a system for making good judgment legible. It is not a system for replacing judgment. And judgment can be wrong.
The levers you pick for your two axes are not self-evident truths. They are informed hypotheses. You derived them from call centre transcripts, or five interviews, or a conversation with the support lead who has heard every complaint twice. That is real signal. It is not infallible signal.
You might have picked the wrong cut of the problem. You might have optimised for the axis that felt obvious and missed the one that actually governs behavior. You might have built four personas that are internally coherent, beautifully named, and pointed at the wrong question entirely.
The only way to find out is to show them to people who will tell you so.

At Club+, I showed the personas to my manager before they went anywhere near a steering committee. He disagreed with parts of them. I disagreed with his disagreement. Some of his objections were right; they changed the personas. Some did not survive contact with what the data actually showed. That back-and-forth was not a formality or a political step. It was the last quality gate before the work became load-bearing.
This is what makes AI-assisted personas genuinely different from AI-generated theater. The theater version goes: prompt, output, present. The real version goes: prompt, output, ground it, socialise it, defend it, refine it, then present it.
That process is not slower in any meaningful sense. The grounding and socialisation together might take a day. What it replaces is the six months of nobody using the personas because nobody was ever convinced they were true.
For someone earlier in their career, this step is not optional; it is load-bearing in a way it is not for someone with twenty years of pattern recognition behind them. The senior designer socialises their levers because they have been wrong before and they know what that costs. The junior designer needs to socialise their levers because they have not yet built the instinct for when the frame is off.
The practical version of this is simple. Before the personas go into any meeting, walk them past three people who know the user differently than you do. The PM. The support lead. A sales rep. Not to get approval. To get resistance. Ask them directly: does this feel true? What does this miss? Who is not in here that should be?
If nobody pushes back, you have not found the right people to show it to.
And when they do push back; hold your ground if the data supports it. That is not stubbornness. That is the job. The persona is not a democracy. It is a defensible position. You built it from signal, you grounded it in behavior, you can explain why the levers are the levers. If someone disagrees, make them show you what the data says differently.

The Club+ personas survived the steering committee because they had already survived my manager. They had been stress-tested before they were load-bearing. By the time they were being presented to a committee that could kill the product, they had already absorbed the obvious objections and come out the other side.
That is what socialization buys you. Not consensus. Durability.
AI compressed the time. Not the thinking.
Here is the claim that needs interrogating.
Synthetic personas are cheap. Fast. Accessible to anyone with a laptop and a Claude tab open. That is true. But cheap and fast describe the generation step — the moment you go from blank page to four named behavioral types with motivations and friction points and a two by two that makes sense.
The generation step is maybe ten percent of the work.
What AI actually compressed is the part that used to be the excuse. The recruiter lead time. The scheduling. The transcription backlog. The three weeks between finishing fieldwork and having anything to show for it. Those costs were real, and they were the reason teams skipped research entirely — not laziness, but a genuine calculation that the time was not available.
That calculation no longer holds.

Five interviews that used to take two weeks to schedule, run, transcribe, and synthesise can now take three days. AI-moderated research can run in parallel across multiple participants. Transcript analysis that used to be a week of manual coding is now an afternoon of interrogating outputs. The time excuse evaporated.
You still have to pick the right levers. You still have to ground them in real signal. You still have to walk the personas through the funnel and ask where the math breaks. You still have to show the work to people who will push back and be willing to change it when they are right. None of that got faster. None of that got easier.
What changed is that you have no reason not to do it.
Before, you could say the research would take six weeks and the sprint was two. That was a real constraint. It forced a genuine trade-off between rigour and speed. Sometimes speed was the right call. Often it was not, but the argument was at least honest.
Now the research takes three days. The sprint is still two weeks. The trade-off argument is gone.
This is the shift that matters most for how teams are structured and how designers are evaluated. The value used to be distributed across the whole process — research took time, so the researcher's time was valuable. Synthesis took skill, so the analyst's skill was valuable. Generation took effort, so the effort was visible and rewarded.
Now generation is table stakes. A junior with a good prompt can produce something that looks like research in twenty minutes. The value has migrated entirely upstream — to the question that preceded the prompt, the signal that grounded the levers, the judgment that decided which behavioral cut was worth making.
That is a harder thing to see on a sprint board. It does not show up as a completed ticket. It shows up six months later when the product is being used in the way the personas predicted, or not used in the way nobody predicted because the levers were wrong and nobody asked.
The teams that understand this are not the ones moving fastest. They are the ones who slowed down in exactly the right place — grounding, socialising, stress-testing — and then moved very fast everywhere else. The generation is the easy part. Give it twenty minutes and move on.
The thinking is the job. Always was.
Start here
This is not a post about AI being good or bad at generating personas.
It is a post about a question that used to be forced by circumstance and now has to be chosen deliberately. The question is simple: how do you know this is true? Before AI, the cost of research made that question unavoidable. After AI, you have to want to ask it.
Everything in the methodology — the two by two, the behavioral levers, the Fogg model, the Markov chain, the socialization — is in service of that one question. The process is not the point. The question is the point.
What you do with that depends on where you are.

If you have been doing this for a while
The instinct is already there. You have built bad personas and watched them go in a drawer. You have built good ones and watched them change a roadmap. You know the difference, even if you have not always been able to name it.
Name it now. Articulate your levers before you generate anything. Write down what signal you are drawing from and what would prove the frame wrong. That discipline is what separates your work from the twenty-minute version — and it is invisible in the output unless you make it visible.
The other thing: socialise earlier than feels comfortable. The personas that survive a steering committee are the ones that have already been argued with. Find the person most likely to disagree and start there.
If you are mid-career and evaluating approaches
You probably already have personas in play; ones the PM commissioned, ones the last designer left behind, ones that emerged from a workshop and never got questioned. The framework here is not asking you to throw those out. It is asking you to point them at something specific.
Pick one live project. Identify the behavior you are trying to change. Map it to ability and prompt. Build four types. Walk them through the flow.
If the PM says "we already have personas," that is your opening, not your obstacle. Pull the existing personas into the two by two. If they do not map to behavioural levers, they are character sketches; and you have just demonstrated why the new frame is worth ten minutes of everyone's time.
Then ask the question your old methodology never forced you to ask: at which step does each persona stall, and why?
If the personas cannot answer that question, the levers are wrong. Go back to the signal. The framework did not fail — the grounding did.
If you are early in your career
You do not need thirty-two interviews. You do not need a data pipeline or a sixty-thousand-dollar research budget. You need five conversations and the discipline to listen for behavior instead of opinion.
Talk to five people. Not about the product; about the problem. Ask where things break down. Ask what they have tried. Ask what stopped them. You will hear the levers before you finish the fifth call.
If you have never run a research conversation, here are three questions that get to behaviour fast:
"Walk me through the last time you tried to [do the thing]. What happened?"
"Where did you get stuck; what did you do next?"
"Was there a point where you gave up or found a workaround? Tell me about that."
Notice what these have in common: none of them ask for an opinion. They ask for a story. Stories contain the friction; opinions hide it.
Then build the two by two. If you have never made one, here is the blank template. The axes come from the Fogg model: Ability (can this person do the thing?) and Prompt Responsiveness (does the trigger actually reach them and move them to act?). Those are the meta-axes; your job is to translate them into the specific form they take in your problem space (at Club+, ability became ability to stay organised; at Compare Club, it became readiness to buy).
High Ability | Low Ability | |
|---|---|---|
High Prompt Responsiveness | Capable and triggered. | Willing but blocked. |
Low Prompt Responsiveness | Able but unreached. | Neither able nor prompted. |
Fill in the cells with real people from your five conversations. If a quadrant stays empty, that is data too; it means your problem space might not split the way you assumed.
Show it to someone who will disagree. Change what the evidence says to change. Hold what the evidence supports.
The methodology is not the craft. The craft is the willingness to be wrong, the humility to check, and the confidence to defend what you actually found.
No blog post gives you that. But this one might convince you it is worth looking for.
One more thing. You do not get into this process by presenting a deliverable. You get into it by asking a behavioural question. In a meeting where the team is debating a feature, do not propose a persona; ask: "Have we thought about what stops people from doing X?" That question does something a slide deck never will; it moves the conversation from opinion to behaviour. And once behaviour is on the table, you are in the room where the levers get decided.
After that, the sentence is five words: "Can I help with any of this?" Not "let me present my research." Not "I built some personas." Just an offer to do the work. Juniors who ask behavioural questions and then volunteer for the grounding step will learn more in three months than a year of solo deliverables would teach them.
And if you are hiring
The candidate who generated twelve personas in an afternoon and presented them with confidence did something impressive. Ask them one question before you decide what it means: where did the levers come from?
If they can answer that — if they can trace the axes back to real signal, articulate what would prove the frame wrong, describe who they showed it to and what changed — you have found someone who understands the difference between generation and judgment.
If they cannot, you have found someone who learned the output without learning the question.
There are faster signals too. Four things to look for in a portfolio or a screening call:
Demographics-led personas are a red flag. If the axes on the two by two are age and income (or gender and tech-savviness, or any other demographic pair), the candidate described people, not behaviour. Behavioural levers govern what someone does; demographics describe who they are. The former predicts friction. The latter predicts nothing useful.
A two by two with named behavioural axes is the strongest signal you will find. It means the candidate made a choice about which cut of the problem mattered, committed to it, and built the personas around it. That is the hard part. Everything downstream is execution.
Eight to twelve personas means they skipped the constraint step. They never asked "how many is useful?" They treated completeness as rigour. Four is almost always right; it forces you to pick the two axes that matter most. More than four usually means every axis got included and none got prioritised.
Finally, one screening question for the AI era: "Tell me about a time an AI output looked right but you decided not to use it. What made you suspicious?" Not "tell me how you use AI" (that tests fluency). Not "what tools do you use" (that tests fashion). This question tests the exact skill that matters; whether the candidate can distinguish plausibility from groundedness and act on the difference. If they have never been suspicious of an AI output, they have never checked one.


